If your SaaS company hasn’t leapt on board the Customer Success train yet, it’s likely due to “focusing on other things,” or “we don’t have the budget for that right now.” But prioritizing a customer success program pays big dividends in returning revenue – so much so that it’s gaining the reputation as the ultimate growth hack. That’s not hype – Customer Success is how SaaS businesses raise retention rates and increase referrals while paving the road for cross-sells and upsells.
Why Should You Establish a Customer Success Program?
If you’re focusing most of your resources on acquisition, you’re missing out on one of the greatest growth engines at your disposal.
“Customer success is where 90% of the revenue is,” – Jason Lemkin, venture capitalist and founder of SaaStr
Customer Retention
Acquisition may get the ball rolling, but retention is where the big money is. Big, sustainable money that costs less and less to make. And, this alchemy only works when customers achieve the successes with the product or service that they’d hoped for upon signing up. Customer success programs are large factors in reducing churn and helping increase long-term customer retention.
Expands Business
Statistically, successful customers:
- Spend more money over time
- Are highly likely to consider additional products and services
- Serve as enthusiastic brand advocates that reduce the Cost to Acquire new customers (CAC)
Easier Future Acquisition
That last point, customer evangelism (aka. brand advocacy), is the most significant benefit of Customer Success and the one that leads to spending less on acquisition efforts, while acquiring more customers.
When your company understands what success means to your customers, then ensures they receive what they need to achieve it, those customers respond – on Facebook, on Twitter, on Yelp, on Linkedin, and in person. They become not just your fans, but your best salespeople, helping your company grow.
But how do you start a customer success program from scratch?
First, let’s start with what customer success really is, because any time a term becomes a “buzzword” it tends to lose its original meaning.
What Is Customer Success?
Customer Success is how you help customers achieve their desired outcomes, even if those outcomes are outside of the product or service you provide.
With this as our definition, Customer Success is really about one thing: Giving your customers everything they need to be successful with your product – within and outside of the product.
For example, if a person downloads a SaaS budgeting app, they don’t want to budget per se, but they do want to pay off their credit card debt and start saving for a kitchen remodel. That is what success means. Not using the app. Not budgeting. But finally running your hands over smooth quartz countertops and showing off that Big Chill refrigerator when the neighbors come over.
That is success. Your product or service is merely the means to get there.
Sure, you can pile more tasks onto your Customer Success department, like planning upsells and cross-sells and customer referral rewards programs. But if you don’t have that one thing in place first – their success – you can’t move onto anything else.

It’s why I advocate building Success Milestones into Product Development’s user flows.
What Are Success Milestones?
Success Milestones are when customers receive value – value that they recognize – from using a product. It’s when that budgeting app customer saves their first thousand towards that Big Chill ‘fridge.
Building Success Milestones into your user flow is a useful way to chart what’s happening within the app and link it to wins happening in real life.
For businesses looking to build a Customer Success program from scratch, this is a key concept. Your process begins by understanding your ideal customer’s real life.
You need to understand how your product fits into their lives, helps them achieve their real-life goals, what frustrates them, and what blocks them from achieving those goals.
Which leads us to Step 1.
How to Start a Customer Success Program
Step 1. Get to know your ideal customer really well (through qualitative data)
When your company was merely a gleam in your founder’s eye, there was (hopefully) a process in place to identify ideal customers and find out what problems they needed to solve, which pain points felt the worst, and what they deeply wanted to achieve.
If your founder followed the Lean Startup methodology, customer interviews happened to ensure product-market/problem-solution fit well before Product Development set to work.
But, if your company skipped those steps, you’ve got a lot of qualitative data to catch up on.

Do not panic. You don’t have to start at the beginning, because you have a product and customers already. What you need to do now is focus on the segment of customers who fit into your ideal customer profile.
Your ideal customers are: Customers who love your product, use it, and tell other people about it because they love it so much.
You can identify which of your existing customers fall into this category by tracking brand mentions, but you can also just ask.
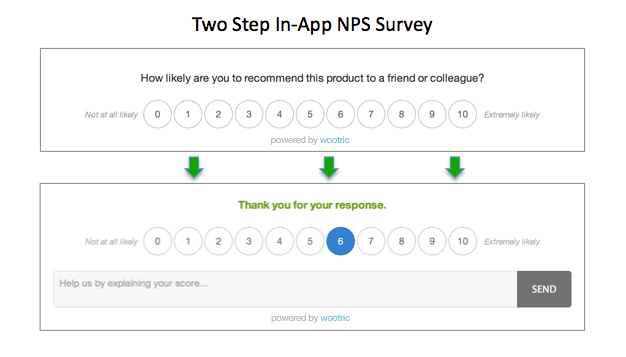
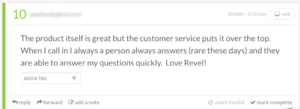
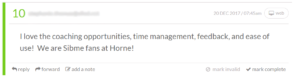
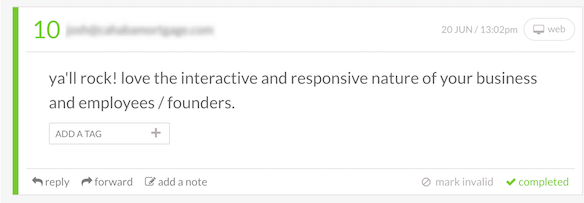
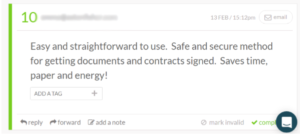
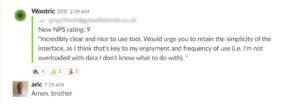
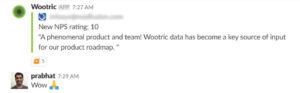
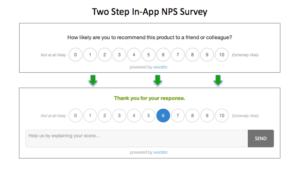
When it comes to identifying your best customers, a Net Promoter Score survey is fast and efficient. You can send the survey via email or within your app (a less disruptive option), and ask existing customers “On a scale of 1 through 10, with 10 being most likely, how likely are you to recommend this product to friends and colleagues?”
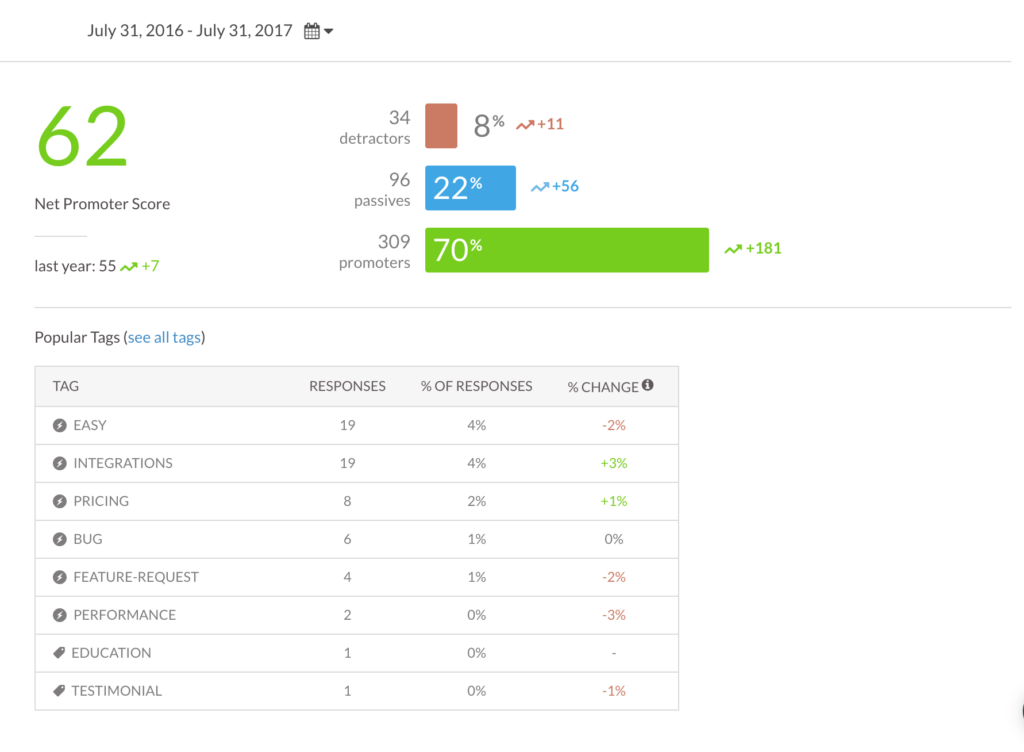
Anyone who scores a 9 or 10 is a “Promoter.”
Promoters are the people we want to speak with when developing Customer Success Program strategies because we know, for certain, that they have problem/solution fit. Not all customers do. Customer Success can only do so much, and if there isn’t that problem/solution fit from the start, you can’t manufacture it. So you have to identify it, attract more of it, and nurture it.
Customer Success is as much about identifying customers likely to be a good fit as it is helping them achieve their ideal outcomes.
Ask some of your Promoters – those who scored 9s and 10s – if they’d be willing to speak with you, or at least fill out a detailed open-ended-question survey, so you can confidently identify your ideal customer’s needs, wants, pain points, ideal outcomes and more. This qualitative data will allow you to create solutions that speak uniquely to them.
Sarah E. Brown, Head of Customer, Community and Brand Marketing at ServiceRocket, uses a Voice of Customer program with NPS to understand how well they’re delivering outcomes for customers and improve marketing at the same time:
“VOC is executed through our marketing function in conjunction with our Customer Success team, and together we are able to identify high NPS customers as brand advocates and follow up with them to create high-value marketing collateral like co-hosted webinars, case studies, podcasts and video testimonials.
Through our NPS review program, we have an incredibly clear picture into our customers who are using our product to achieve successful outcomes. Then we channel them into becoming vocal advocates who bring in new customers and help current customers love our software even more.”
Step 2. Build Your Team
Once you understand who you’re serving and what they’re trying to achieve, you need to put your team together. Sure, you could hire an experienced Customer Success manager or consultant, but you can also look inside your own building – at the Sales department.
A good salesperson already knows your product and your customers, which makes for a relatively easy transition. The key, however, is to shift the sales mindset from selling the product to setting up customers for success.
That can be a substantial challenge. Because sometimes, a customer’s success won’t come from being upsold, and it can run counter to the salesperson’s gut instincts to not jump at an immediate sale, and say “Hey, your company is on the smaller side. I don’t think you need this additional service yet. So let’s focus on how we can help you grow to the point where this service would be really useful.”
Customer Success can, sometimes, mean delayed gratification. But the loyalty you build by giving advice that is 100% to the customer’s benefit is priceless.
When assembling your Customer Success team, there are a couple more very important characteristics to watch out for: You’ll need people who are good team players and great communicators, because the most effective Customer Success teams are those that work closely with Sales, Service and Product to find ways to bridge success gaps.
Step 3. Determine What Structure You Need to Help Customers Reach Their Ideal Outcomes
If you have the resources, investing in a full-service Customer Success platform, like Gainsight, is a great way to begin. But these solutions can be out of reach, budget-wise. If that’s the case, then you may have to DIY and create your own processes.
Things you’ll need to consider:
- Customer segments – do you have one “ideal customer” or an “ideal customer” for each user segment?
- Do your user segments require different levels of help to reach their ideal outcomes? Often, one segment of users needs a higher-touch approach than another segment (and no, you shouldn’t base higher-touch vs. lower-touch solely on how much the segment pays – a lower paying segment might have high-paying potential with the right nudge).
- What are the desired outcomes for each segment? Do they require different resources to reach them?
- How do you intend to track customer health? What can you identify as “red flags” of disengagement?
- Do you have a way to mark different customers according to their life stage – and whether/when they are reaching their Success Milestones?
- If you have an existing product and the ability to track user behavior within it, where do users drop off?
- Is there a process in place to identify when certain Success Milestones are reached and present opportunities for logical upsells?
- Where are success gaps happening for each segment? (A success gap is the space between what your product does and the user achieving his or her desired outcome).
Step 4. Must-Have Metrics
- Customer Lifetime Value (LTV) is the foundation for a strategy to increase ROI and sustain growth, but its shortest definition is: The revenue earned from a single customer over time. LTV includes Cost to Acquire a new Customer (CAC) and Churn rate – how quickly customers leave. However, most calculations fail to include cross-sells, up-sells, and the value of referrals for each customer, which increase LTV. To affect LTV, your marketing strategies should take these other factors into account as well. LTV is, perhaps, the most important metric CSMs in subscription-based businesses can track because it’s the best at predicting success… or failure. Cost to Acquire (CAC) is intimately connected with LTV because if your CAC is higher than or equal to your LTV, your business is FAILING! The Cost to Acquire number comes from tracking metrics like manufacturing costs, research, development, and marketing – everything you need to convince a potential customer to buy. While the equation is simple enough – just divide the total costs of acquisition by total new customers within a specified time period – adding up every acquisition-related activity is where companies get bogged down.
- Net Promoter Score (NPS) works better than churn to score how well you’re doing at delivering desired outcomes. Sometimes, an unhappy customer won’t get around to churning – the effort is just too low on their to-do list. But if you ask that customer if they’d recommend you to a friend (the NPS question is “How likely are you to recommend us to a friend or colleague?”), you’ll get an honest answer. Many NPS platforms also allow you to segment your surveys for even deeper insights. This is a great number to use if you haven’t got time to creat a complex customer health score system.
- Churn is important to track, but more so in the context of understanding what causes churn and how you can proactively prevent churn. Yes, you need to know how many people are leaving. But that number is too little, too late. What you really need to track are the leading indicators of churn.
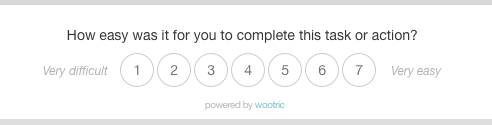
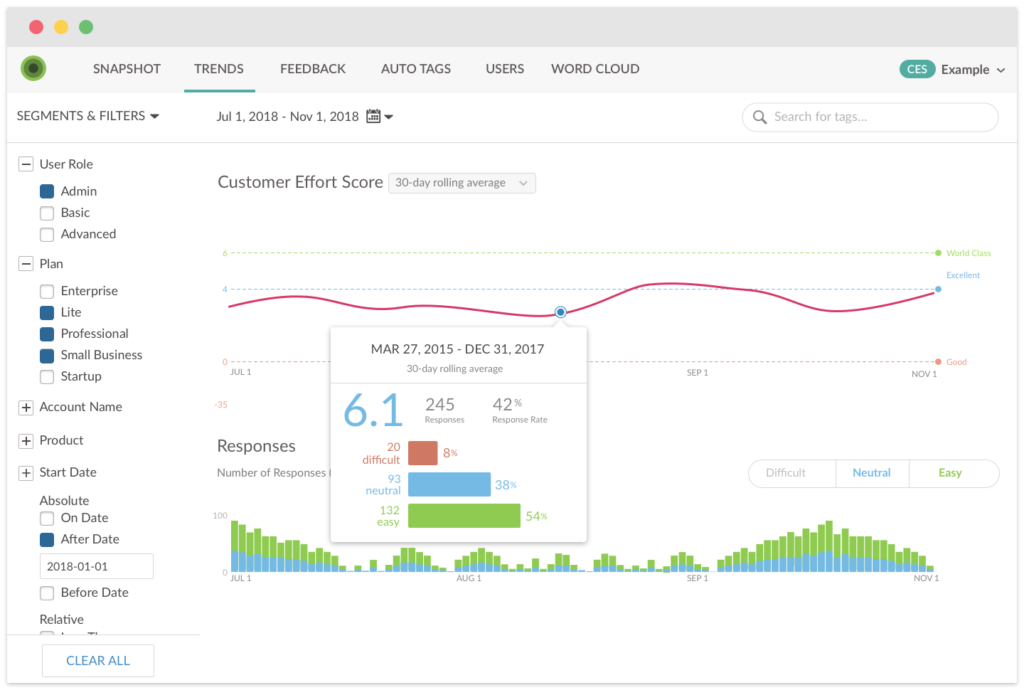
- Customer Effort Score – Traditionally used by support teams, CES can also be used to get feedback on user experience in onboarding, new feature setup, and to identify obstacles to users finding value.
Setting up an NPS program? Get the ebook, The Modern Guide to Winning Customers with Net Promoter Score. Leverage customer feedback and drive growth with a real-time approach to NPS.
There are others. Groove reduced churn by 71% by using what they called “red flag” metrics, including:
- Length of first session
- Frequency of logins
- Total number of logins
- Time spent on individual tasks (the longer the time spent, the more trouble the user is probably having, and the more likely they are to churn)
Whatever metrics you track, essentially, you need to know how well your customers are doing at any given time, identify when they’re experiencing success, be alerted when they run into trouble, and have a plan in place for helping them to grow and succeed even more (by using more of your product when it can benefit them).
It’s helpful to plan all of this within the context of the Product department’s user flows, which brings us to…
Step 5. Collaborate
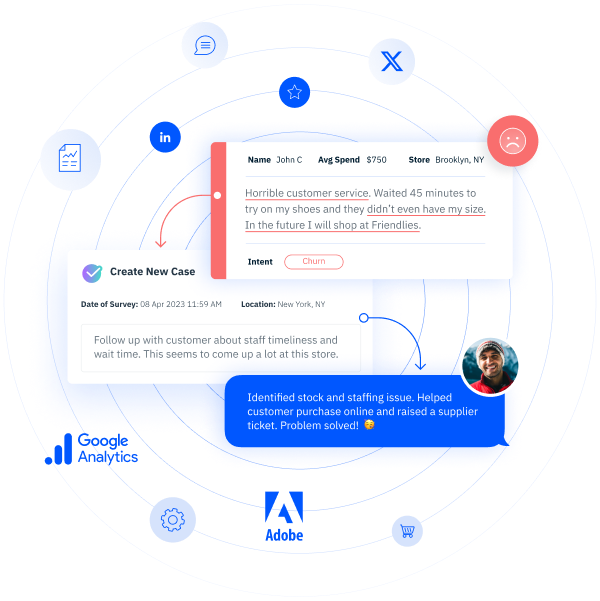
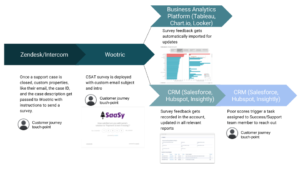
Customer Success can’t do its best work separated off from other departments, keeping its data in a silo. It won’t do you any good to collect all of this data on your customers if you can’t share what you learn with departments able to act on that information.
To really begin to see the results of your Customer Success program, you’ll need to open lines of communication with Sales, Customer Service and Product Development so you can work together to identify and bridge success gaps for customers. Better yet, invite one person from each department to be part of the Customer Success team.
One example of effective collaboration is between Product and Customer Success. Customer Success needs Product Development to address product-specific success gap issues, and Product Dev needs to understand the broader concept of ideal outcomes, and where success gaps are occurring, from Customer Success. A good place to start collaborating is to align behind customer feedback. Use that to start discussions and to lay the foundation for the solutions you can find together.
When you bring these two departments together, you can achieve all of that and more, like building in Success Milestones into the app itself so users can track their own successes (and sales teams can keep tabs on their progress and introduce upsell suggestions when they make sense).
Step 6. Focus on One Thing at a Time
Is it retention after onboarding? Identifying upsell opportunities? Filling success gaps? Once your customer success program is set up, it can be hard to figure out what to focus on next. Kayla Murphy, Customer Growth, Advocacy and Success at Trustfuel works with early-stage Customer Success teams and recommends focusing on one thing at a time.
“Start with one focus and build processes to go with it. Institute QBRs (Quarterly Business Reviews) or regular check-ins. Start tracking your usage data and figuring out which metrics give you the best picture of customer health.
Just start.
Many of the teams I work with felt a great deal of analysis paralysis at the beginning of their customer success journey. They were worried about annoying customers, tracking the wrong metrics, or focusing so much on unhealthy accounts that morale dies. You have to start somewhere and no one knows more about your customers right now than you. Start being proactive and consistently evaluate your processes.”
Just start, perhaps, is the best advice.
How it All Works Together
Let’s pretend that customer acquisition is a game of “Who can prove their worth the fastest?”
The players are you and your competitors.
When a new user signs up to try your product, it triggers a series of events – the goal of which is proving your worth before that user gets bored and signs up with your competition.
When a new user signs up…
– The new user receives a welcome email from a Customer Success agent who asks them what they would most like to achieve with your product.
– The new user is impressed that somebody cares (they care! They really care!) and replies: “I’d like to sell more balloon poodles at the next county fair.”
– The Customer Success agent replies “I love balloon poodles! So cool! Would 50 more balloon poodles be a realistic starting goal for the next 3 months?”
See what happened there? The customer success agent keys in on the new customer’s desired outcome, then creates a specific, measurable, attainable goal that they can keep track of. Maybe there’s even a page built into the website that helps the customer track their own progress towards their goal.
These steps don’t need to happen over email (although this is exactly what Slack does during onboarding). They can happen within your product too. Or a combination, like using a simple in-app how-to program to guide newbies through their first several actions. Then you might use customer feedback on their desired outcomes to send them an appropriate ebook or link to relevant blog posts to help them achieve it.
Essentially, you prove your worth by making your customer’s success a priority – and making sure they know it!
Build an effective customer success program with Pearl-Plaza today.






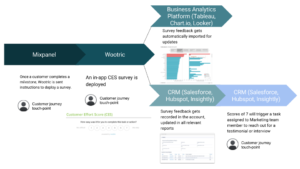
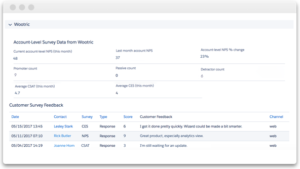









 The
The